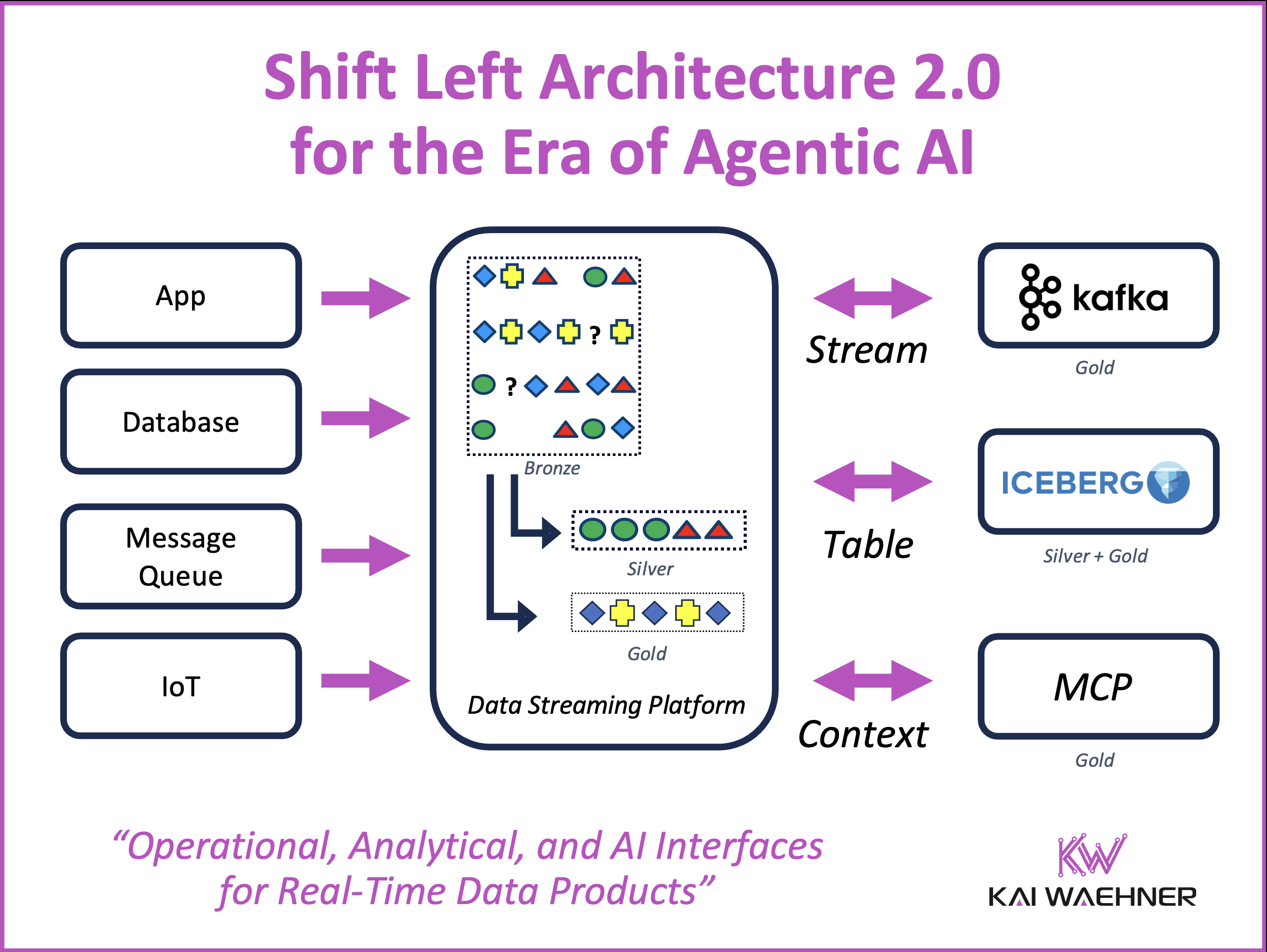
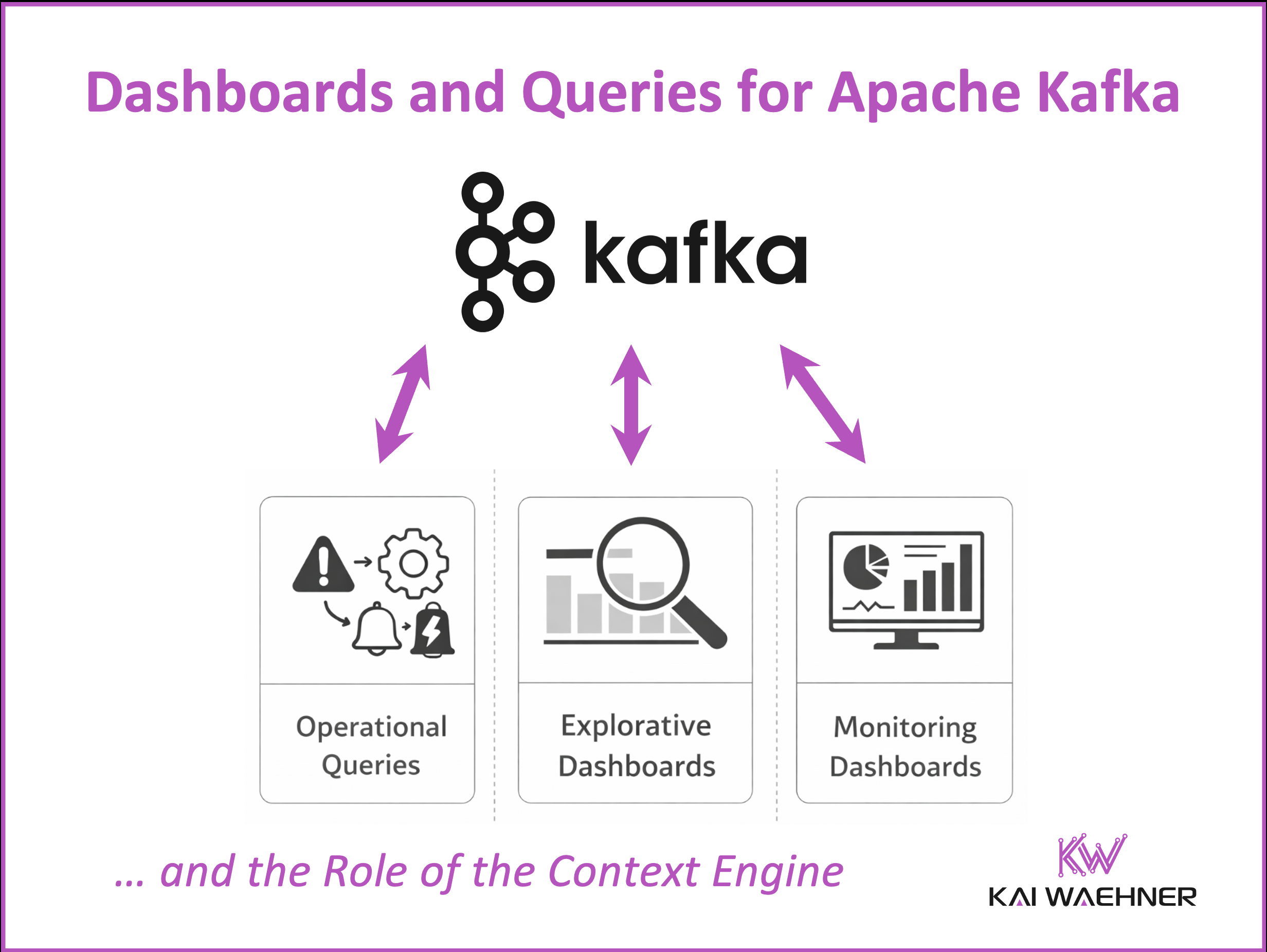
Apache Kafka
This blog explores how Confluent and Databricks address data integration and processing in modern architectures. Confluent provides real-time, event-driven pipelines connecting operational systems, APIs, and

This blog explores how Confluent and Databricks address data integration and processing in modern architectures. Confluent provides real-time, event-driven pipelines connecting operational systems, APIs, and

Data integration is a hard challenge in every enterprise. Batch processing and Reverse ETL are common practices in a data warehouse, data lake or lakehouse.

The integration between Apache Kafka and Snowflake is often cumbersome. Options include near real-time ingestion with a Kafka Connect connector, batch ingestion from large files,

SAP is the leading ERP solution across industries around the world. Data integration with other data platforms, applications, databases, and APIs is one of the
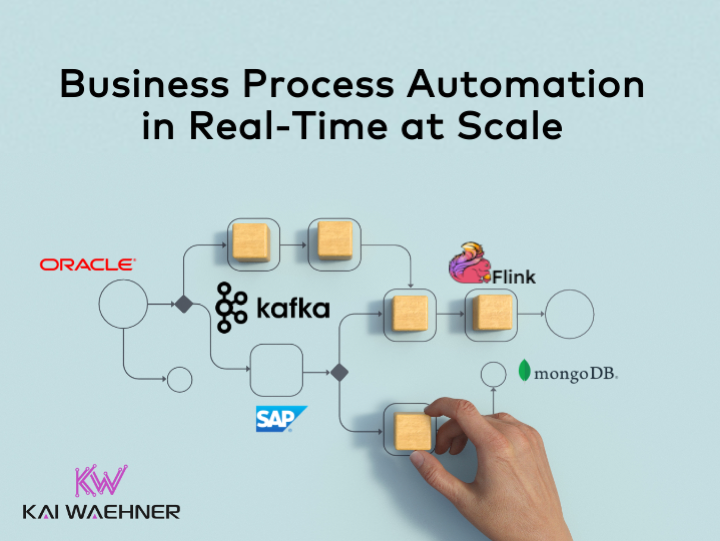
Business process automation with a workflow engine or BPM suite has existed for decades. However, using the data streaming platform Apache Kafka as the backbone

Real-time data beats slow data in almost all use cases. But as essential is data consistency across all systems, including non-real-time legacy systems and modern

IT modernization and innovative new technologies change the healthcare industry significantly. This blog series explores how data streaming with Apache Kafka enables real-time data processing