Allgemein
Apache Iceberg is gaining momentum as the open table format of choice for modern data architectures. In this blog post, the key takeaways from my

Apache Iceberg is gaining momentum as the open table format of choice for modern data architectures. In this blog post, the key takeaways from my

Confluent, Databricks, and Snowflake are trusted by thousands of enterprises to power critical workloads—each with a distinct focus: real-time streaming, large-scale analytics, and governed data

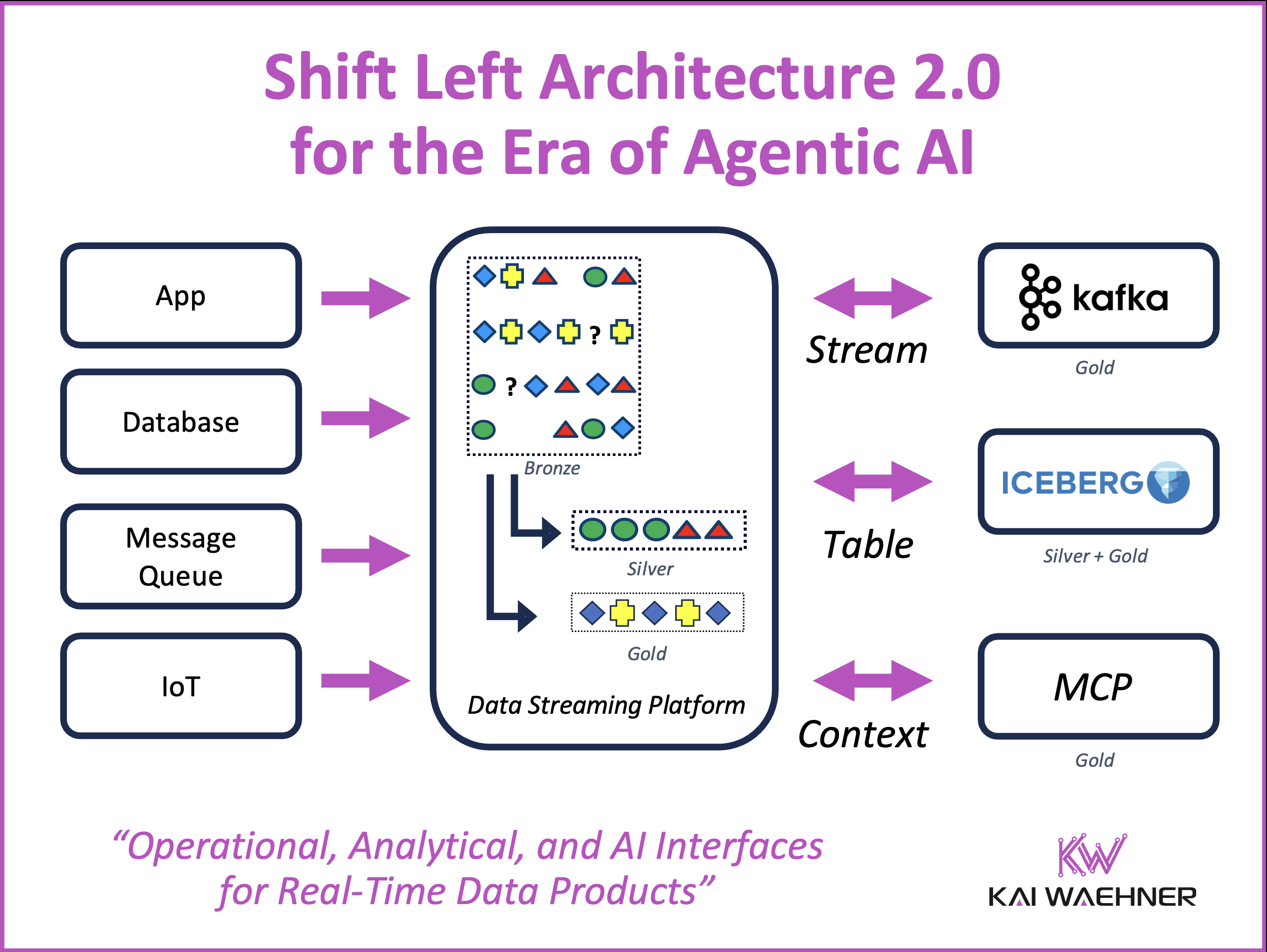
Confluent and Databricks enable a modern data architecture that unifies real-time streaming and lakehouse analytics. By combining shift-left principles with the structured layers of the

Batch processing introduces delays, complexity, and data quality issues that modern businesses can no longer afford. This article outlines the most common problems with batch

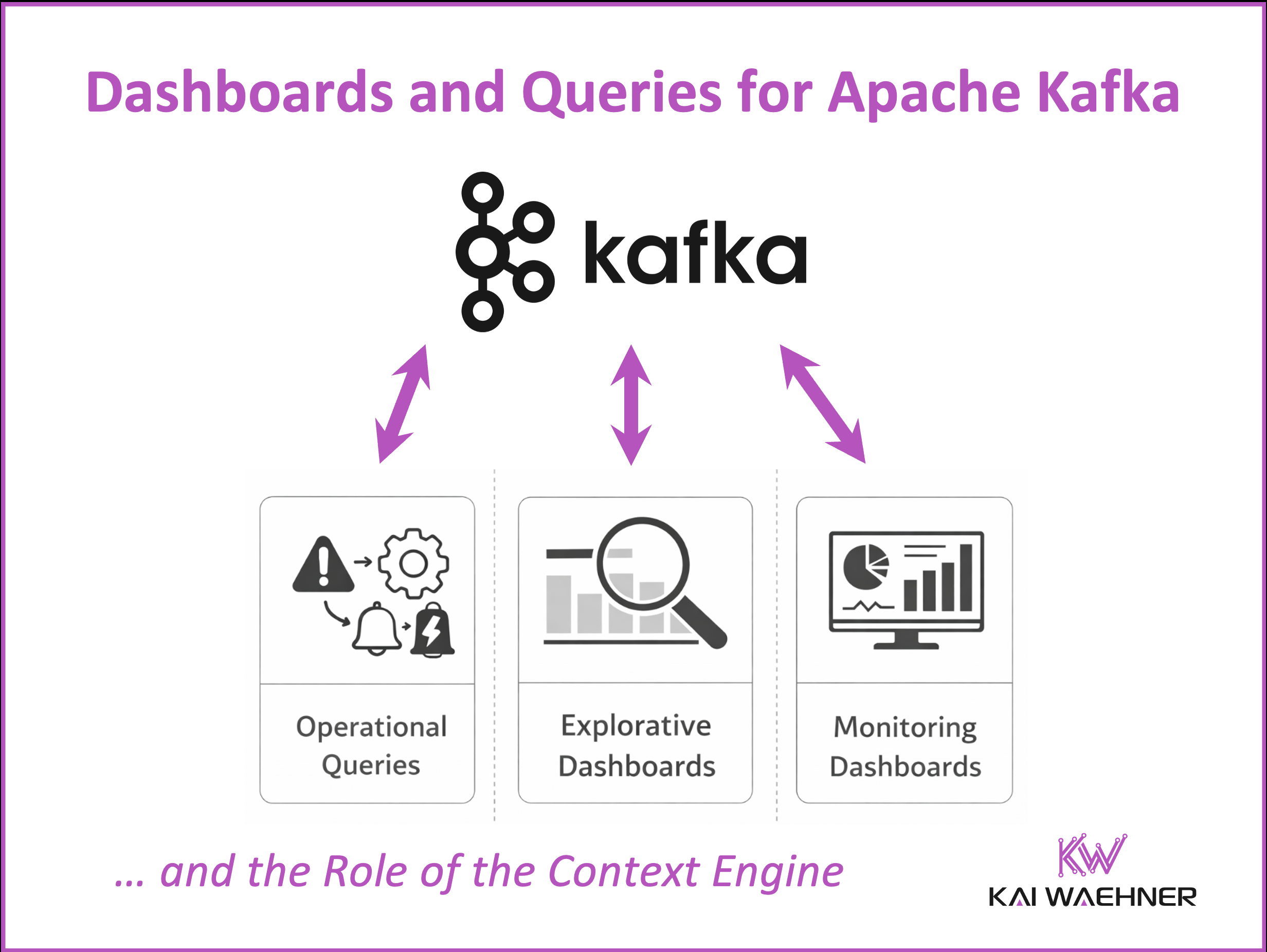
In today’s data-driven world, understanding data at rest versus data in motion is crucial for businesses. Data streaming frameworks like Apache Kafka and Apache Flink

If you ask your favorite large language model, Microsoft Fabric appears to be the ultimate solution for any data challenge you can imagine. That’s also
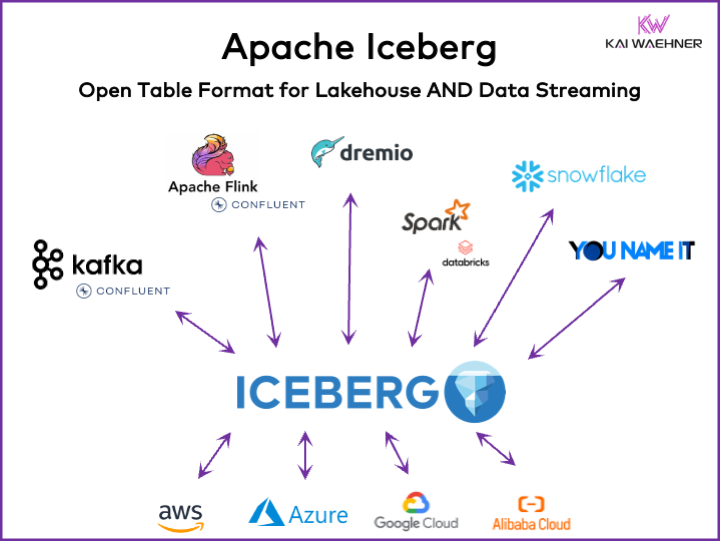
An open table format framework like Apache Iceberg is essential in the enterprise architecture to ensure reliable data management and sharing, seamless schema evolution, efficient

Data integration is a hard challenge in every enterprise. Batch processing and Reverse ETL are common practices in a data warehouse, data lake or lakehouse.

If there were a buzzword of the hour, it would undoubtedly be “data mesh”! This new architectural paradigm unlocks analytic and transactional data at scale

The concepts and architectures of a data warehouse, a data lake, and data streaming are complementary to solving business problems. Unfortunately, the underlying technologies are