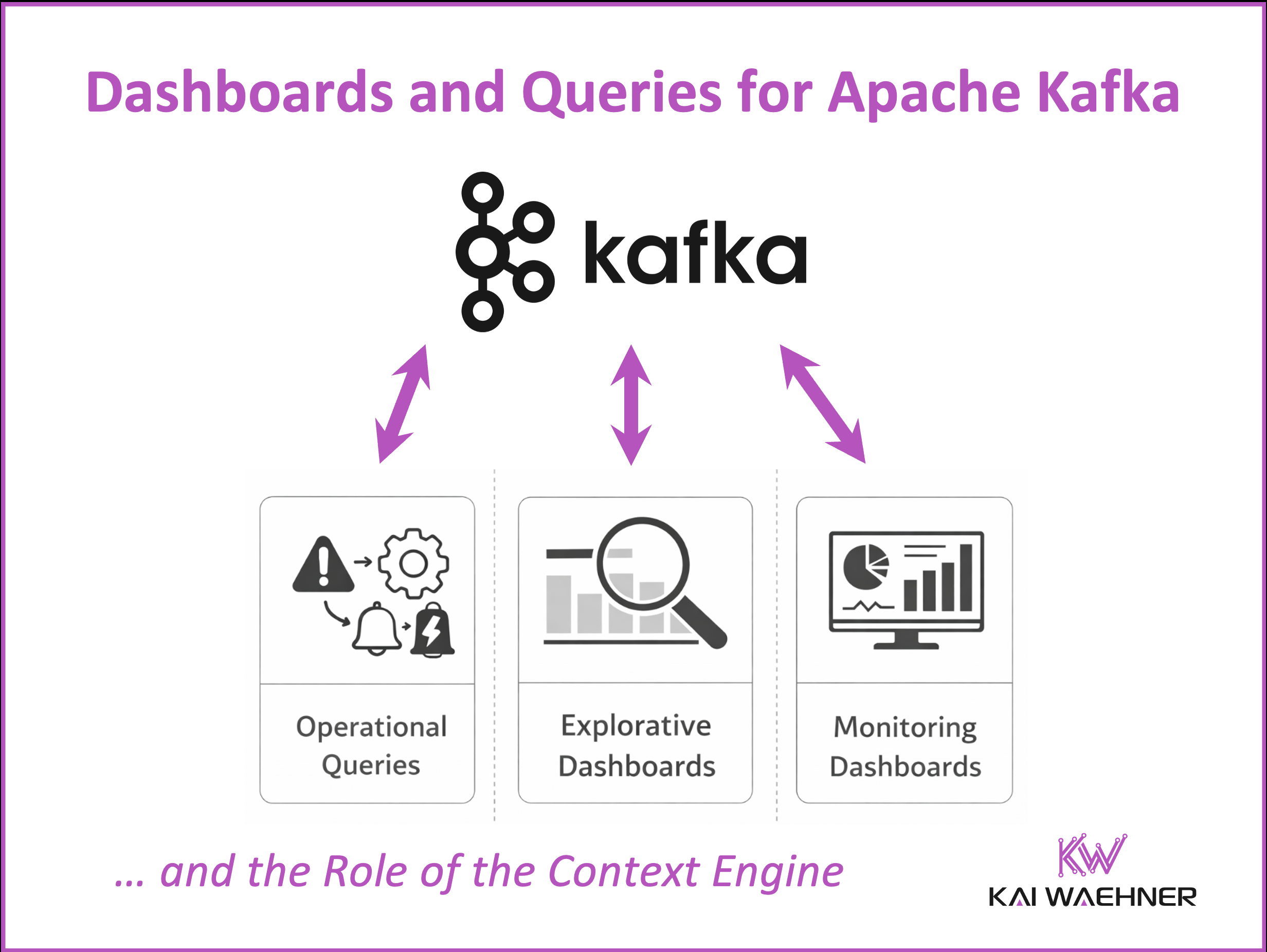
Apache Kafka
This blog explores how Confluent and Databricks address data integration and processing in modern architectures. Confluent provides real-time, event-driven pipelines connecting operational systems, APIs, and

This blog explores how Confluent and Databricks address data integration and processing in modern architectures. Confluent provides real-time, event-driven pipelines connecting operational systems, APIs, and
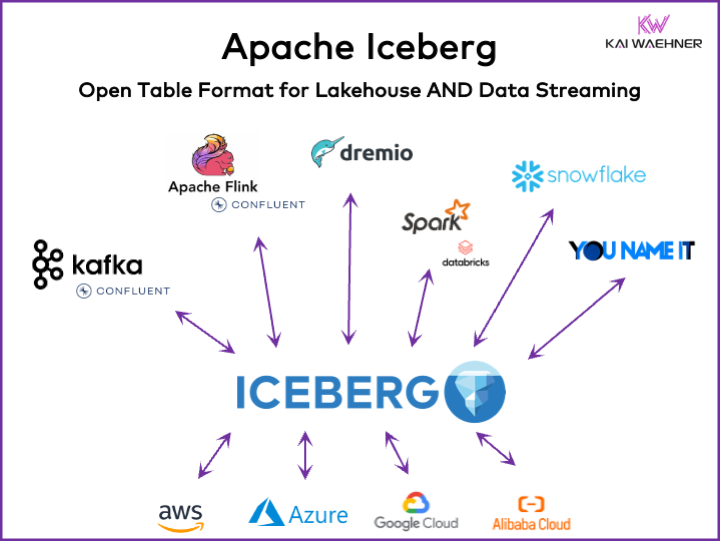
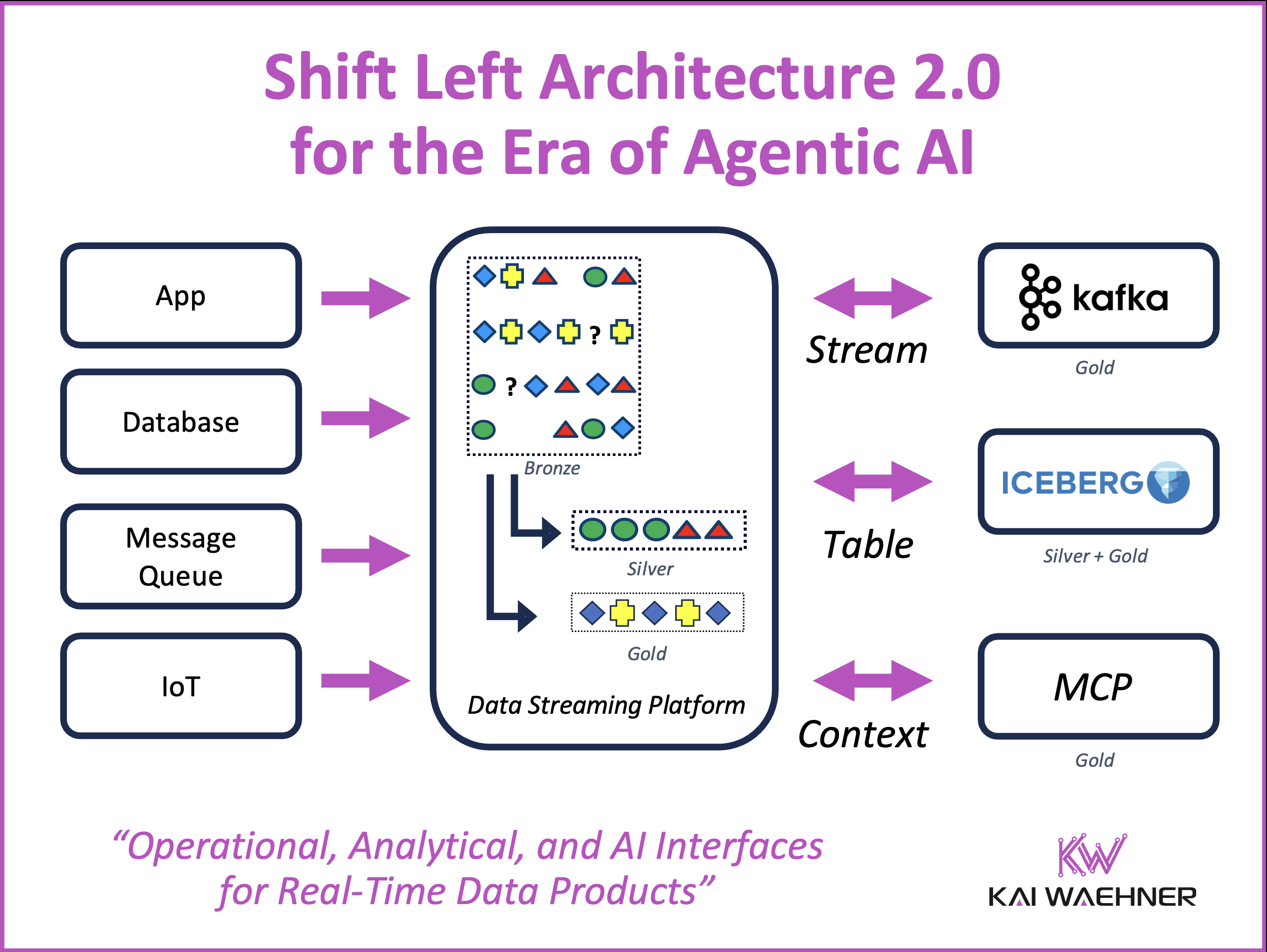
An open table format framework like Apache Iceberg is essential in the enterprise architecture to ensure reliable data management and sharing, seamless schema evolution, efficient

Data integration is a hard challenge in every enterprise. Batch processing and Reverse ETL are common practices in a data warehouse, data lake or lakehouse.
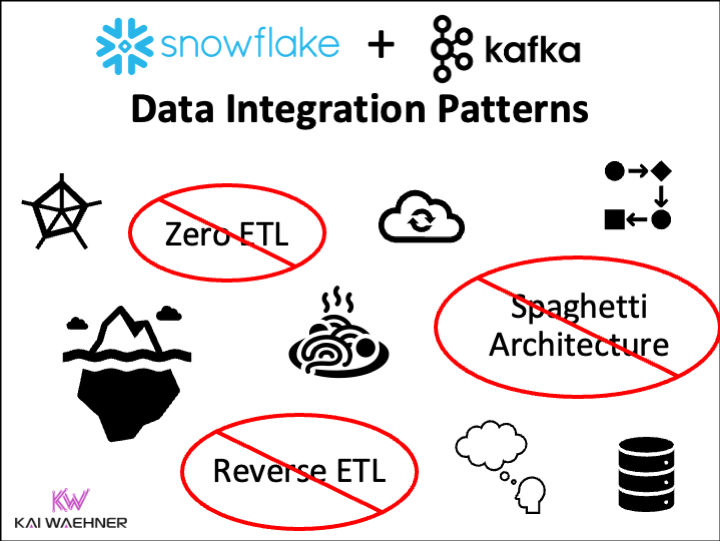
Snowflake is a leading cloud-native data warehouse. Integration patterns include batch data integration, Zero ETL and near real-time data ingestion with Apache Kafka. This blog

This blog post explores why software vendors (try to) introduce new solutions for Reverse ETL, when Reverse ETL is really needed, and how it fits